기술기고문
디지털 신호 프로세서에 통합된 온 칩 FIR 및 IIR 하드웨어 가속기 활용 모델과 그 효과
글: 미테시 무낫(Mitesh Moonat) 애플리케이션 엔지니어,
산켓 나약(Sanket Nayak) 애플리케이션 엔지니어 / 아나로그디바이스(Analog Devices, Inc.)
개요
FIR(finite impulse response)과 IIR(infinite impulse response) 필터는 가장 널리 사용되는 디지털 신호 처리 알고리즘으로서, 특히 오디오 프로세싱 애플리케이션에 많이 쓰인다. 통상적인 오디오 시스템에서는 프로세서 코어 시간의 상당 부분이 FIR과 IIR 필터링에 사용된다. 디지털 신호 프로세서 상에 FIRA 및 IIRA라 불리는 온칩 FIR 및 IIR 하드웨어 가속기를 사용하면 FIR 및 IIR 처리 부담을 덜 수 있어, 코어는 그 만큼 다른 작업을 처리할 수 있다. 이 글에서는 이러한 가속기들을 어떻게 활용할 수 있는지 다양한 활용 모델과 실시간 사례들을 이용해 살펴본다.
Introduction

그림 1: FIRA 및 IIRA 시스템 블록 다이어그램
그림 1은 FIRA와 IIRA의 개략적인 블록 다이어그램과 이들 가속기가 프로세서 시스템 및 나머지 자원들과 어떻게 상호작용하는지 보여준다.
▶ FIRA와 IIRA 블록은 모두 주로 MAC(곱셈-적산) 유닛 같은 연산 엔진으로 이루어지고, 작은 로컬 데이터 및 계수 RAM을 가지고 있다.
▶ 초기화 과정에서 코어는 FIRA/IIRA 프로세싱의 입력을 담당할 DMA 전송 제어 블록(TCB) 체인을 초기화한다. 동작 루틴마다 코어는 DMA의 포인터를 잡아주고 FIRA/IIRA 동작을 시작시킨다. FIRA/IIRA가 모든 프로세싱을 완료하고나서, 코어로 인터럽트를 통해 알린다. 이후 코어는 해당 결과를 다른 동작을 위해 처리된 출력을 사용할 수 있다.
▶ 이론적으로는 모든 FIR 및 IIR 작업을 코어에서 가속기들로 옮기고 코어가 병렬로 다른 작업을 하게 하는 것이 가장 좋은 방법이다. 하지만 코어가 추가적인 프로세싱을 병렬로 처리해야 할 작업이 없을 때는 해당하지 않는다. 따라서 이런 경우, 최상의 결과를 달성할 수 있도록 적합한 가속기 활용 모델을 선택해야 한다.
이제 이들 가속기를 서로 다른 애플리케이션에 최적으로 활용하기 위한 다양한 모델들을 살펴보기로 한다.
실시간으로 FIRA 및 IIRA 사용
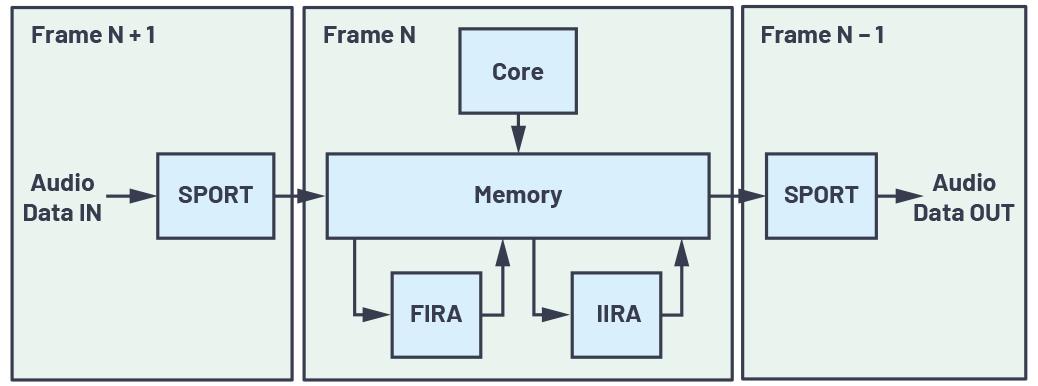
그림 2: 통상적인 실시간 오디오 데이터 플로우
그림 2는 통상적인 실시간 PCM 오디오 데이터 플로우 다이어그램을 보여준다. 디지털화된 PCM 오디오 데이터의 1개 프레임이 동기식 직렬 포트(SPORT)를 통해 수신된 다음, DMA(direct memory access)를 통해서 메모리로 전송된다. N+1번째 프레임이 수신되는 동안, N번째 프레임은 코어와 가속기에 의해 처리되고, 이보다 먼저 처리된 프레임(N-1)의 출력은 디지털-아날로그 변환을 위해 SPORT를 통해서 DAC로 전송된다.
가속기 활용 모델
앞서 말했듯이, 코어의 FIR 및 IIR 처리 부담을 최대한 덜고 코어 사이클을 최대한 절약해서 다른 작업에 사용할 수 있도록 하기 위해서는 애플리케이션에 따라서 가속기 활용 방법이 달라져야 한다. 가속기 활용 모델은 크게 다음의 세 가지 범주로 구분할 수 있다. 직접 대체, 작업 분담, 데이터 파이프라이닝이 그것이다.
직접 대체
▶ 코어의 FIR 및 IIR 프로세싱 작업은 가속기가 직접 대체하고, 코어는 가속기들이 작업을 완료하기를 기다린다.
▶ 이 모델은 가속기가 코어보다 FIR 및 IIR 프로세싱 작업을 더 빠르게 처리할 수 있을 때만 효과적이다.
작업 분담
▶ FIR 및 IIR 프로세싱 작업을 코어와 가속기가 분담한다.
▶ 이 활용 모델은 여러 채널을 병렬로 사용할 수 있을 때 특히 유용하다.
▶ 타이밍을 어림으로 계산해서 둘이 비슷한 시간에 작업을 완료하도록 코어와 가속기 간에 총 채널 수를 나누어 배분한다.
▶ 그림 3에서 보듯이, 이 활용 모델은 직접 대체 모델에 비해서 코어 사이클을 더 많이 절약할 수 있다.
데이터 파이프라이닝
▶ 코어와 가속기 간의 데이터 플로우를 파이프라이닝해서 둘이 병렬로 서로 다른 데이터 프레임을 처리하도록 할 수 있다.
▶ 그림 3에서 보듯이, 코어가 N번째 프레임을 처리한 다음, 이 프레임을 가속기로 넘긴다. 그리고 나서 코어는 가속기가 전 사이클에서 제공한 N-1번째 프레임의 출력을 추가적으로 병렬 처리한다. 이러한 시퀀스는 FIR과 IIR 프로세싱 작업을 전적으로 가속기에 맡길 수 있으나, 그 대신 이번 스캔에서 처리된 결과가 다음 스캔에서 나가게 되므로 추가적인 출력 지연시간이 발생한다.
▶ 전체 프로세싱 체인에서 파이프라인 스테이지 수와 그로 인한 출력 지연시간은 이와 같은 FIR 및 IIR 프로세싱 스테이지 수에 따라 늘어날 수 있다.
그림 3은 다양한 가속기 활용 모델에서 DMA IN, 코어/가속기 프로세싱, DMA OUT의 3개 스테이지 간에 오디오 데이터 프레임이 어떻게 이동하는지를 보여준다. 서로 다른 가속기 활용 모델에 따라서 FIR/IIR 프로세싱 작업의 일부 또는 전체를 가속기에 맡김으로써 절약되는 코어 사이클이 얼마나 늘어나는지 알 수 있다.
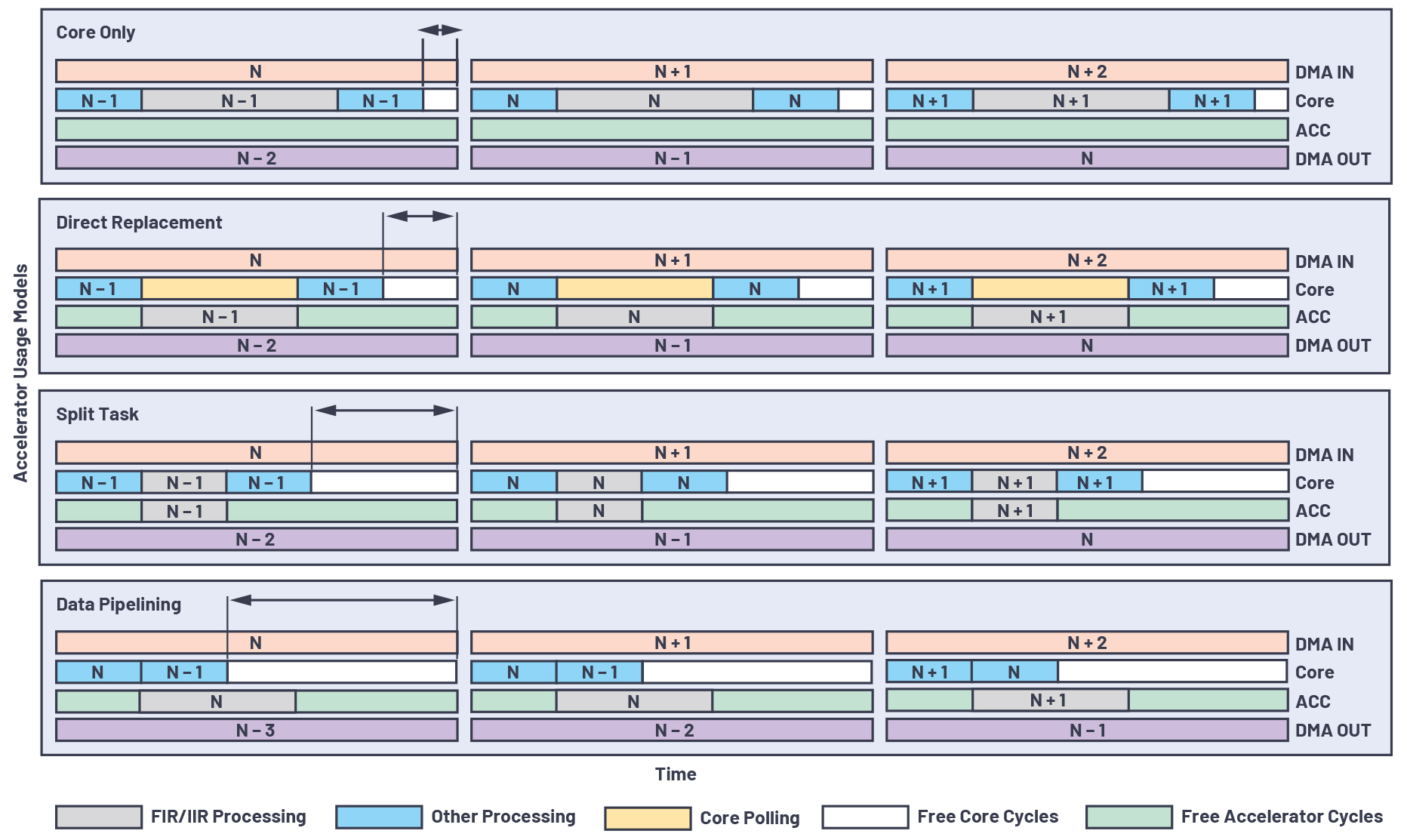
그림 3: 가속기 활용 모델 비교
SHARC 프로세서에 통합된 FIRA와 IIRA
아나로그디바이스(Analog Devices)의 다음과 같은 SHARC® 프로세서 제품군은 FIRA와 IIRA를 온 칩 형태로 통합하고 있다(오래된 제품부터 최신 제품 순).
▶ ADSP-214xx (ADSP-21489 포함)
전체 제품군에 걸쳐, 이들 제품은 다음과 같은 특징을 나타낸다:
▶ 연산 속도는 제품마다 다르다.
▶ ADSP-2156x 프로세서의 자동 구성 모드(ACM)를 제외하고, 기본적인 프로그래밍 모델은 동일하다.
▶ FIRA는 4개의 MAC 유닛을 사용하고, IIRA는 단일 MAC 유닛을 사용한다.
ADSP-2156x 프로세서에서의 FIRA/IIRA 향상
ADSP-2156x는 SHARC 프로세서 제품군에 가장 최근에 추가된 제품이다. 최초의 1GHz 단일 코어 SHARC 프로세서이며, FIRA와 IIRA 역시 1GHz가 가능하다. ADSP-2156x 프로세서는 ADSP-SC58x/ADSP-SC57x 프로세서에 비해서 FIRA와 IIRA가 여러 면에서 향상되었다.
성능 향상
▶ 연산 속도가 기존 자사 모델 대비 8배 높아졌다(SCLK-125MHz에서 CCLK-1GHz로).
▶ 전용 코어 패브릭을 사용해서 코어와 가속기를 가깝게 배치함으로써 코어와 가속기 사이에 데이터 및 MMR 액세스 지연시간을 줄였다.
기능 향상
ACM(자동 구성 모드)을 지원하므로 가속기 프로세싱에 필요한 코어 개입을 최소화한다. 이 모드는 다음과 같은 새로운 기능들을 가능하게 한다:
▶ 동적 작업 큐잉을 위해서 가속기를 중지할 수 있다.
▶ 무제한적인 채널 수가 가능하다.
▶ 트리거 생성(마스터)과 트리거 대기(슬레이브)가 가능하다.
▶ 각 채널에 선택적인 인터럽트 생성이 가능하다.
시험 결과
이제 ADSP-2156x 평가 보드를 사용해서, 서로 다른 가속기 활용 모델을 갖는 두 가지 실시간 다채널 FIR/IIR 활용 사례 결과를 살펴보자.
활용 사례 1
그림 4는 활용 사례 1의 블록 다이어그램을 보여준다. 샘플 레이트는 48kHz이고, 256 샘플을 모아서 1 블록을 구성한 후 처리하는 방식이다. 본 사례의 작업 분담 모델의 경우, 코어 대 가속기에 할당한 채널의 비는 5:7이다.
표 1에서는 측정된 코어 및 FIRA MIPS와, 코어만 사용할 때에 비해 절약된 코어 MIPS를 볼 수 있다. 활용 모델에 따라서 출력 지연시간이 추가된다는 것도 알 수 있다. 표에서 보듯이, 가속기를 사용하는 데이터 파이프라이닝 활용 모델로 최대 335 코어 MIPS를 절약할 수 있는 대신, 1블록(5.33ms)의 출력 지연시간이 발생한다. 직접 대체와 작업 분담 활용 모델도 각각 98 MIPS와 189 MIPS를 절약하며 추가적인 출력 지연시간을 일으키지 않는다.
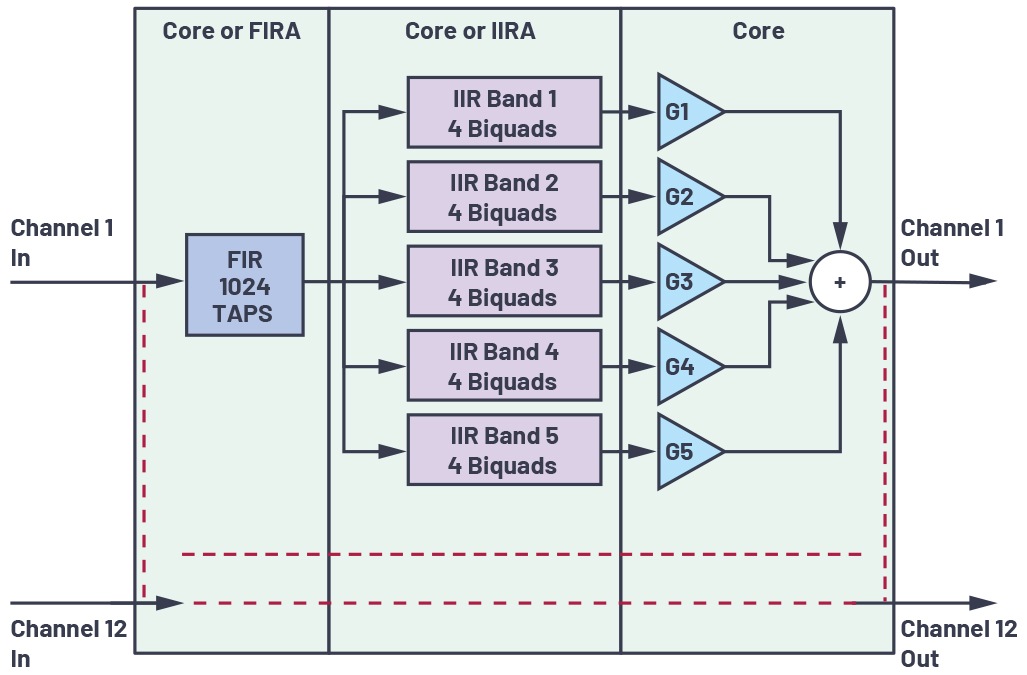
그림 4: 활용 사례 1의 블록 다이어그램
표 1: 활용 사례 1에 대한 코어 및 FIR/IIRA MIPS 요약
| 활용 모델 | 코어 MIPS | FIRA MIPS | IIRA MIPS | 코어 MIPS 절약 | 활용 모델 지연시간 (ms) |
| 코어만 사용 | 337 | 0 | |||
| 직접 대체 | 239 | 162 | 75 | 98 | 0 |
| 작업 분담 | 148 | 96 | 44 | 189 | 0 |
| 데이터 파이프라이닝 | 2 | 161 | 75 | 335 | 5.33 (1 프레임) |
활용 사례 2
그림 5는 활용 사례 2의 블록 다이어그램을 나타낸다. 샘플 레이트는 48kHz이고, 128 샘플을 모아서 1블록을 구성 후 처리하는 방식이다. 본 사례의 작업 분담 모델의 경우, 코어 대 가속기 채널 비는 1:1이다.
표 2에서 이 활용 사례의 결과를 볼 수 있다. 가속기를 사용함으로써 데이터 파이프라이닝 활용 모델에서 최대 490 코어 MIPS를 절약할 수 있지만 그 대신 1블록(2.67ms)의 출력 지연시간이 발생한다. 작업 분담 활용 모델은 추가적인 출력 지연시간을 발생시키지 않고 234 코어 MIPS를 절약한다. 활용 사례 1에서와는 다르게, 이 사례에서 가속기는 해당 작업을 시간 도메인 프로세싱으로 처리하기 때문에, 코어가 같은 작업을 주파수 도메인(고속 컨볼루션) 프로세싱 하는 것보다 느리다. 한 개의 채널을 처리하는 데 드는 코어만 사용 모델 상의 코어 MIPS가 직접 대체 모델의 FIRA MIPS보다 적게 나타나는 (더 빠른) 이유가 바로 이 때문이다.
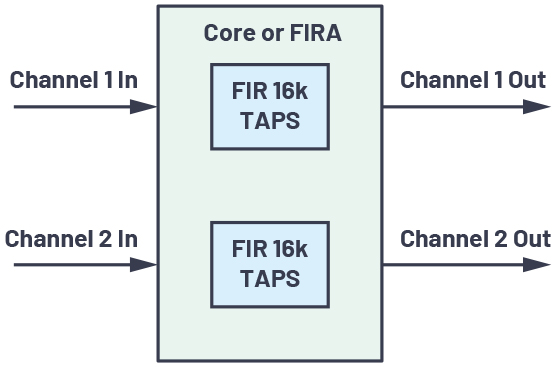
그림 5: 활용 사례 2의 블록 다이어그램
표 2: 활용 사례 2의 코어 및 FIR MIPS 요약
| 활용 모델 | 코어 MIPS | FIRA MIPS | 코어 MIPS 절약 | 활용 모델 지연시간 (ms) |
| 코어만 사용 | 493 | 0 | ||
| 직접 대체 | 515 | 511 | –22 | 0 |
| 작업 분담 | 259 | 257 | 234 | 0 |
| 데이터 파이프라이닝 | 3 | 511 | 490 | 2.67 (1 frame) |
맺음말
이 글에서는 ADSP-2156x 프로세서 상에 FIRA와 IIRA를 활용함으로써 서로 다른 가속기 활용 모델에 따라 얼마나 많은 코어 MIPS를 절약할 수 있는지 살펴보았다.
###
저자 소개
미테시 무낫(Mitesh Moonat)은 아나로그디바이스 인도 뱅갈로르(ADBL) 지사 프로세서 애플리케이션팀의 애플리케이션 엔지니어이다. SHARC® 프로세서 검증, 주변장치 드라이버 개발, 지원을 맡고 있다. 그 전에는 Blackfin®과 ADSP-21xx 프로세서 제품을 담당했다. 프로세서 아키텍처, 디지털 신호 프로세싱 알고리즘 최적화, 모듈, 임베디드 시스템 디버깅과 관련해서 풍부한 경험을 쌓고 있다. 2006년에 아나로그디바이스에 입사했으며, 인도 와랑갈 소재 국립 공과대학에서 전자공학 및 통신공학 학사학위를 취득했다. 문의: mitesh.moonat@analog.com
산켓 나약(Sanket Nayak)은 아나로그디바이스 인도 뱅갈로르(ADBL) 지사 프로세서 애플리케이션팀의 제품 애플리케이션 엔지니어이다. 2016년에 ADI에 입사했으며, 자동차 DSP 검증, 드라이버/FuSa ROM 설계, 개발, 테스트와 관련된 업무를 맡았다. 뱅갈로르의 P.E.S 공과대학에서 전자공학 및 통신공학 학사학위를 취득했다. 문의: sanket.nayak@analog.com
제품스펙