Technical Article
제품 및 Tools
비바도(Vivado) IPI, 오로라(Aurora) 디자인을 위한 공유 가능한 FPGA 리소스 시대를 열다
비바도(Vivado) IPI, 오로라(Aurora) 디자인을 위한 공유 가능한 FPGA 리소스 시대를 열다
2016-02-22
고객들이 대규모 디자인을 위해 IP(Intellectual Property)의 다중 인스턴스를 이용해 단일 FPGA 상에 구현해야만 하는 경우 직면하게 되는 가장 큰 도전과제 중 하나는, 어떻게 이 리소스들을 시스템 전반에 걸쳐 효과적으로 공유할 것인가 하는 문제일 것이다.
자일링스(Xilinx®)의 오로라(Aurora) 시리얼 통신 코어는 다중 인스턴스들에 걸쳐 공유된 리소스를 제공한다. 비바도 디자인 수트(Vivado® Design Suite)에서 제공되는 IPI(IP Integrator) 툴은 이러한 공유 리소스를 최대한 활용할 수 있도록 해주는 핵심 툴이다.
전자산업은 고속 시리얼 커넥티비티 솔루션 기반으로 빠르게 변화하고 있으며, 병렬 통신 표준은 점차 자리가 좁아지고 있다. 산업 표준 시리얼 프로토콜은 고정된 라인속도와 정의된 레인 폭을 가지고 있어, 기가비트 시리얼 트랜시버의 성능을 충분히 활용하지 못하는 경우가 많다.
오로라는 자일링스의 고속 시리얼 통신 프로토콜로써 여러 산업 분야에서 폭넓은 지지를 받고 있으며, 구현이 너무 복잡하거나 또는 지나치게 리소스-집약적인 경쟁 프로토콜들의 애플리케이션에 전형적으로 사용되고 있다. 오로라는 저비용의 고속 데이터 전송속도와 확장 가능한 IP 솔루션을 제공함으로써 고속 시리얼 데이터 채널을 유연하게 구현할 수 있는 솔루션이다.
라인 속도와 채널 폭을 모두 확장해야 하는 고성능 시스템 및 애플리케이션은 솔루션으로서 오로라를 고려하고 있다. 또한 오로라는 기가비트 데이터 전송 백플레인(backplane)을 갖춘 복수의 FPGA 기반 시스템은 물론, ASIC 디자인에도 적용되고 있다. 오로라의 간단한 프레임 구조와 프로토콜-확장형 플로우 제어 기능은 기존 프로토콜의 데이터를 압축(encapsulate)하는데도 사용할 수 있다. 전기적 요건은 상업용 장비와 호환이 가능하다. 자일링스는 비바도 디자인 수트 IP 카탈로그에서 Aurora 64b66b (64비트-66비트 부호하) 및 Aurora 8b10b (8비트-10비트 부호화) 코어를 제공하고 있다.
비바도 IPI는 복잡한 멀티코어 시스템에서 리소스를 최적화하기 위한 핵심 툴이다. 이러한 점에서 IPI는 특히 ‘공유-로직(Shared-Logic)’ 기능을 통해 Aurora 64b66b 및 Aurora 8b10b 코어의 공유 가능한 리소스를 최대한 활용할 수 있도록 해준다. 편의상, 이 글에서는 Aurora 64b66b IP를 다루기로 하며, Aurora 8b10b 코어 또한 동일한 기법을 적용할 수 있다.
오로라의 공유 가능한 리소스 요약
그림 1은 Aurora 64b66b 코어의 블록 다이어그램을 나타낸 것이다. 강조된 부분은 MMCM(Mixed-Mode Clock Manager), BUFG, IBUFDS와 같은 클럭킹 리소스와 자일링스 7 시리즈 디바이스 기반의 2-레인 디자인을 위해 GT1 및 GT2로 나타낸, GT Common 및 GT 채널과 같은 GT(Gigabit Transceiver) 리소스이다.
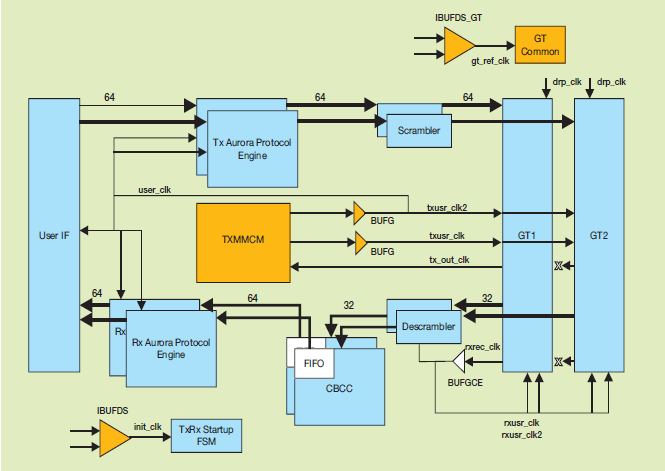
그림 1. Aurora 64b66b 코어에서 공유 가능한 리소스(오렌지색 부분)
킨텍스-7(Kintex®-7) FPGA KC705 평가키트(Evaluation Kit)에서 사용된 것처럼, 전형적인 16-레인 Aurora 64b66b 코어를 위한 클럭킹 및 GT 리소스 요건은 표 1에 정리되어 있다.
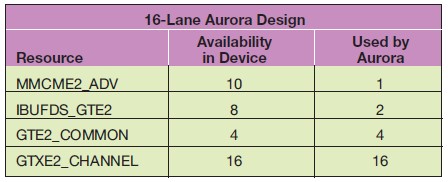
표 1. Kintex-7 FPGA KC705 평가 키트 상에서 클럭킹 및 GT 리소스 활용도
FPGA의 클럭킹 및 GT 리소스는 선택된 디바이스 및 패키지에 따라 다르다. 종종 다중 IP 코어는 시스템 레벨에서 사용할 수 있는 리소스를 필요로 한다. 따라서 시스템 비용은 물론, 전력소모를 절감할 수 있도록 이러한 귀중한 리소스들을 활용할 수 있도록 최적화하는 것은 필수요건이 되었다.
오로라 리소스 공유
다중 GT-기반 자일링스 코어 전반에 걸쳐 지원되는 공유-로직 기능의 일부처럼, 오로라 코어는 ‘코어의 공유 로직(마스터)’ 또는 ‘예제 디자인의 공유 로직(슬레이브)’ 중 하나로 구성이 가능하다. 두 구성을 조합하면, 클럭킹 및 GT 리소스를 시스템 레벨에서 예시화된 마스터 및 슬레이브에 모두 공유하는 것이 가능하다.
공유-로직 기능이 사용되는 애플리케이션의 경우, 여러 개의 IP를 수작업을 연결하게 되면 오류가 발생할 수 있고, 전반적인 디자인-진입(design-entry) 시간이 증가하게 된다. 이러한 디자인 진입 문제를 해결하기 위한 방법은 툴의 지원을 받는 것이며, 자일링스의 IPI는 이를 명쾌하게 해결할 수 있다.
IPI 툴은 top-level 블록처럼 코어를 가상화하며, 표준 인터페이스 포트 간의 연결은 보다 직관적이고, 인텔리전트하며, 때로는 자동화도 가능하다. 툴 및 IP에 통합되어 있는 적절한 DRC(Design Rule Check)를 통해 잘못된 연결을 하이라이트해주고, 디자이너가 이를 디자인 진입 단계에서 확인할 수 있도록 해준다. Top-level wrapper 파일과 적절한 pin-level I/O 요건 추론은 자동으로 이뤄지며, 시스템 디자이너에게 뛰어난 툴 생산성을 제공한다. 만약 커스텀 서브-블록을 디자인하는 경우라면, 자일링스 애플리케이션 노트 1168(‘Packaging Custom AXI IP for Vivado IP Integrator(XAPP1168)’)에서 언급한 것처럼 해당 디자인의 패키징을 고려할 수도 있으며, IPI에서 서브 블록을 이용할 수도 있다.
오로라의 공유-로직 기능으로 다중 인스턴스에 걸쳐 사용자들이 리소스를 공유할 수 있도록 하는 것은 물론, GT Common, PLL, 클럭킹 및 관련 모듈을 편집할 필요없이 동일한 GT 쿼드에서 즉각적으로 GT 채널을 활용할 수 있도록 해준다. 유일한 제약조건은 ‘공유된’ 코어의 라인 속도가 동일해야 한다는 것이다.(클럭킹 리소스 상에서 패널티를 감수할 수 있다면, 배합도 허용된다.)
전형적인 공유-로직 디자인은 하나의 마스터와 하나 이상의 슬레이브 인스턴스가 쿼드 내에 포함된다. 대부분의 다른 통신 IP와 달리, 오로라는 싱글-쿼드 공유에 제한이 없으며, 오로라 코어를 위한 공유-로직 정의는 지원되는 레인 수에 따라 확장이 가능하다. 오로라의 공유-로직 기능에 기반한 몇 가지 애플리케이션 사례를 소개한다.
복수의 싱글-레인 기반 디자인
단일 FPGA 상의 싱글-레인 기반의 복수 디자인은 채널 결합(bonding)을 필요로 하는 멀티레인 디자인과는 다르다. 직관적으로, 시스템 레벨에 선형적으로 추가되는 싱글-레인 기반의 복수 디자인에 필요한 리소스는 분명하게 이해될 수 있을 것이다. 그렇다면 다른 시나리오들을 살펴보고, 공유-로직 기능이 각 경우에 어떠한 도움을 주는지 알아보자.
우리는 4개의 싱글 레인을 갖춘 디자인으로 시작할 것이다. 이러한 종류의 디자인은 4개의 싱글-레인 오로라 코어를 구성하여 간단하게 구현할 수 있다. 이러한 구현을 실제로 살펴보면, 각 오로라 디자인은 하나의 GT Common 인스턴스를 가지고 있기 때문에, 이 디자인의 배치 및 리소스 활용은 4개의 GT 쿼드 전반으로 확대된다. 이는 리소스-집약적이기 때문에 항상 적절한 솔루션이 되기는 어렵다. 전력 및 리소스 측면에서 뛰어난 배치 및 최적화된 솔루션을 구현하기 위해서는 동일한 GT 쿼드에서 4개의 GT가 선택되어야 한다.
공유-로직 기능을 사용하지 않고, 이러한 요건에 부합하는 디자인을 수작업으로 생성한다면 상당한 노력이 수반될 것이다. 공유-로직 기능을 효과적으로 사용하기 위해, 그림 2에 나타낸 것처럼, 마스터 모드에 하나의 오로라 코어를, 그리고 슬레이브 모드에는 다른 3개의 오로라 코어를 생성해야 한다. 또한 마스터 코어가 슬레이브 코어와의 클럭킹을 제어하기 때문에 코어 리세팅과 같은 추가적인 시스템 레벨 고려사항들을 감안해야 한다. 이러한 구성 및 리소스 최적화는 오로라 코어가 동일한 라인 속도로 구성되어 있는 경우에만 즉각적으로 수행 가능하다. 표 2는 시스템에서 4개의 싱글-레인을 디자인하기 위해 공유-로직 기능을 사용한 경우 얻을 수 있는 혜택을 수치화했다.
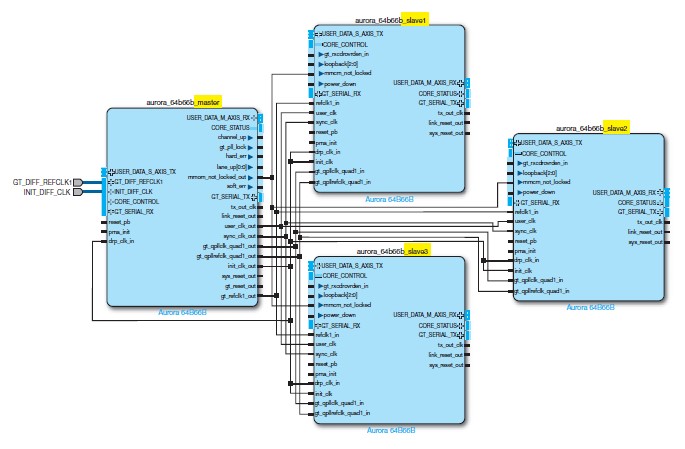
그림 2. 하나의 마스터 오로라 코어(좌측)와 3개의 슬레이브를 이용한 공유-로직 디자인
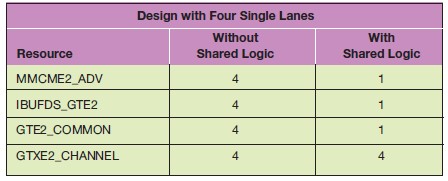
표 2. 4개의 싱글 레인을 갖춘 디자인에서 공유-로직을 통한 리소스 사용 혜택
12개의 GT 채널을 사용하는 디자인
7 시리즈 FPGA의 경우, 남-북 방향의 클럭킹 기반의 GT는 하나의 레퍼런스 클럭 소스로, 이는 중간 쿼드에서 선택되었다면 최대 12개의 GT 채널까지 제공할 수 있다.
그렇다면, 가능한 적은 수의 클럭킹 리소스를 활용해야 하는 12개의 싱글-레인 디자인 요건을 가진 사례를 살펴보자. 그림 2에 보여진 것처럼, 만약 하나의 마스터와 3개의 슬레이브로 구성으로 확장한다면, 클럭킹 리소스를 줄일 수 있다. 하지만 이러한 1+3 구성이 3개의 쿼드로 확장된다면, 이 디자인은 총 6개의 차동-클럭킹 (differential clocking) 리소스가 필요하게 된다. 하지만 싱글-엔디드 INIT_CLK 및 GT 레퍼런스 클럭을 수용할 수 있는 2개의 마스터 디자인을 선택한다면, 좀 더 줄이는 것도 가능하다. 이러한 방법은 시스템에서 차동-클럭 입력 요건을 6개에서 2개로 줄일 수 있으며, IBUFDS/IBUFDS_GTE2 리소스 요건을 줄일 수 있다.(표 3 참조) 이 디자인의 IBUFDS_GTE2 리소스 감소는 실제로 외부 클럭킹 리소스는 물론, 디자인 핀아웃 절감으로까지 이어진다. 유사한 최적화 방법을 MMCM에도 적용할 수 있다.
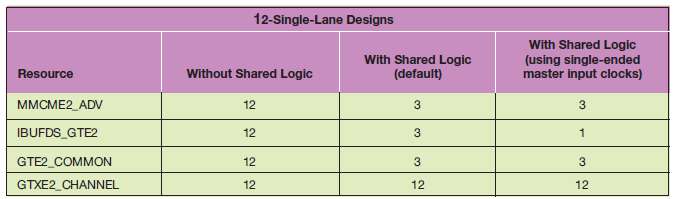
표 3. 12개의 싱글 레인을 갖춘 디자인에서 공유-로직 기능을 통한 리소스 혜택
3x4 레인 디자인
만약 3x4 레인 디자인 요건이 필요한 경우, 공유-로직 기능을 사용하지 않고, 마스터 모드에서 3x4 레인 오로라 코어를 생성할 수도 있으며, 그런 다음 클럭킹 리소스 활용을 최적화하기 위해 수작업으로 디자인을 생성할 수도 있을 것이다. 그렇다면 즉각적으로 동일한 결과를 달성할 수 있다면 어떻게 할 것인가? 그림 3에 나타낸 것처럼, 하나의 마스터 코어와 2개의 슬레이브 코어를 원하는 형식으로 바로 할 수 있다.
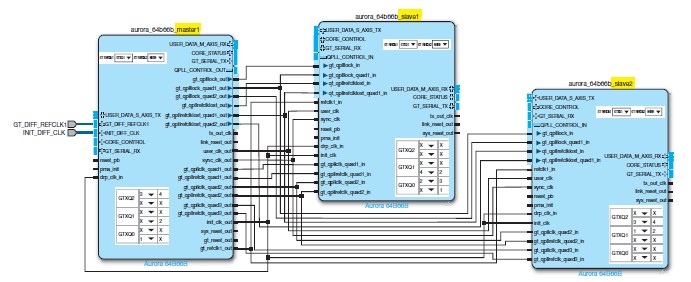
그림 3. 3개의 연속 쿼드 기반의 4-레인 오로라 디자인을 위한
하나의 마스터와 2-슬레이브 컨피규레이션
대형(16개 이상의) 싱글-레인 오로라 디자인의 크기 문제를 고려한다면, 공유 로직의 필요성은 더욱 더 중요해진다. 간혹 48개의 싱글-레인 기반의 독립적인 듀플렉스 (duplex) 링크를 필요로 하는 대규모 디자인이 있을 수 있다. 오로라의 허용 가능한 싱글-레인 링크의 수는 선택된 디바이스에서 이용 가능한 GT 리소스 수에 따라서만 제한된다. 따라서 이 경우, 공유-로직 기능을 효과적으로 사용하지 않고, 이러한 시스템 디자인을 실현하기는 어렵다.
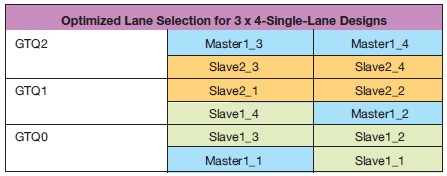
표 4. 3x4 레인 디자인을 위한 최적화된 레인 선택
이 디자인은 12 쿼드까지 확산되기 때문에, 2*12 차동-클럭킹 리소스가 필요하게 되며, 이는 보드 디자인 측면에서 상당히 어려운 작업이 될 수 있다. 12개의 싱글-레인 디자인 사례에서 언급한 기법을 사용함으로써, 시스템 전반의 차동 클럭 및 MMCM 요건을 줄일 수 있다.(표 5 참조)
비대칭 레인 및 또 다른 커스텀 최적화
비디오 프로젝터와 같은 애플리케이션에서, 메인스트림 (mainstream) 데이터는 높은 처리량으로 한 방향에서 처리되며, 낮은 처리량의 비정규 채널(Back Channel)은 정보를 제어하거나 보조 전송을 위해 사용된다. 이러한 애플리케이션에서 완벽한 기능의 듀플렉스 링크를 갖추게 된다면, 대역폭 사용량을 훨씬 더 줄일 수 있으며, 이를 통해 시스템 디자인의 ROI 비용을 낮출 수 있게 된다. 이러한 형태의 문제에 적합한 솔루션은 그림 4에 나타낸 것처럼, GT 리소스 활용을 최적화한 비대칭 링크 폭이 해결책이 될 수 있으며, 한 방향의 데이터 플로우(보다 높은 처리량)의 레인 수는 다른 방향(낮은 처리량)의 레인 수보다 더 높아질 수 있다.
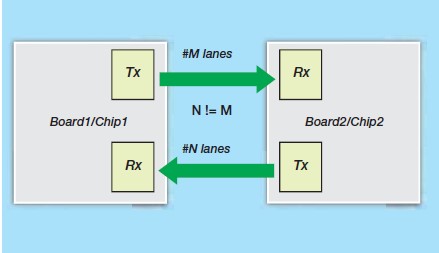
그림 4. 오로라를 이용한 링크 간의 비대칭 데이터 전송 가능
현재 오로라 코어에서 이용 가능한 데이터 플로우 모드(심플렉스/듀플렉스)로는, 동일한 수의 TX 및 RX 레인으로만 코어를 구성하는 것이 가능하다. 두 방향으로 다른 수의 레인을 만들기 위해서는 각 방향을 위한 2개의 오로라 심플렉스 코어를 생성해야 한다. 7 시리즈 FPGA에서 이러한 종류의 비대칭 레인 디자인을 구현하는 방법은 자일링스 애플리케이션 노트 - ‘Asymmetric Lane Design with Aurora 64B/66B IP Core’(XAPP1227)에서 확인할 수 있다.
또 다른 유용한 디자인 전략은 BUFG 리소스 최적화이다. 동일하거나, 또는 서로 다른 라인 속도로 동작하는 다중 오로라 코어를 구현하는 시스템 디자이너는 디바이스에 특화된 클럭킹 요건 및 제한사항을 알고 있어야 한다. 수많은 오로라 링크를 구현하기 위해서는 각각의 링크에 대한 클럭도 생성해야 하며, 이러한 클럭킹 리소스를 보전하는 것은 시스템을 보다 비용 효과적으로 구현할 수 있도록 해준다. 만약 시스템 디자인이 여러 블록을 가지고 있고, 클럭킹 리소스가 부족하다면, BUFG를 BUFR/BUFH로 대체하는 것도 고려할 수 있다. 권고사항이기는 하지만, 동일한 버퍼 타입으로 GT 코어의 유저 클럭 및 TX 경로를 모두 드라이브할 수 있다.
7 시리즈 오로라 코어는 부가적인 DRP(Dynamic Reconfiguration Port) 클럭 입력이 필요한 반면, 하나의 BUFG 만을 사용해야 한다. 오로라의 프리-러닝(Free-Running) 클럭 주파수를 허용 가능한 DRP 클럭 범위 내에서 선택했다면, 오로라에서 이용 가능한 출력 프리-러닝 클럭은 재사용이 가능하고, DRP 클럭과 다시 연결할 수 있다. 이를 통해 생성된 디자인의 BUFG 수를 절감할 수 있다.
다중 오로라 디자인에서 라인 속도를 선택할 때, 링크 전반에 걸쳐 공유 및 클럭 파생이 보다 용이하도록 라인 속도가 정배수가 되었다면, 클럭킹 리소스를 공유할 수 있다는 점에 주목하자. 공유-로직 기능이 하모닉 라인 속도를 확장했다면, 몇몇 외부의 클럭 분배기에 디자인함으로써 슬레이브 오로라 코어를 위해 필요한 입력 주파수를 생성할 수 있다.
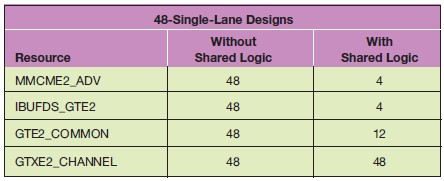
표 5. 48개의 싱글-레인 디자인을 위한 공유-로직 기능의 리소스 혜택
미래의 가능성
오로라의 유연성은 다양한 시스템 구성 및 애플리케이션을 구현할 수 있는 새로운 가능성을 열었다. 자일링스의 비바도 IPI와 같은 강력한 툴의 지원으로 디자인 엔트리 레벨의 생산성 및 시스템 레벨의 리소스 공유가 실현됨으로써 올 프로그래머블(All Programmable) 애플리케이션 분야의 혁신이 가속화되고 있다. 자일링스의 울트라스케일(UltraScale™) 아키텍처 기반의 디바이스들은 보다 많은 GT 채널과 향상된 GT 라인 속도를 갖추고 있으며, 이를 통해 리소스 활용의 가능성 및 효용성은 훨씬 더 높아지고 있다.
오로라 코어에 대한 평가는 IP 카탈로그와 IPI, 그리고 오로라 제품정보 웹 페이지에서 확인할 수 있다.
글/ 크리쉬나 디팩(K Krishna Deepak) 수석 디자인 엔지니어,
디네쉬 쿠마르(Dinesh Kumar) 수석 엔지니어링 매니저,
자야람 PVSS(Jayaram PVSS) 수석 엔지니어링 매니저,
케탄 메타(Ketan Mehta) 수석 IP 제품 매니저,
디네쉬 쿠마르(Dinesh Kumar) 수석 엔지니어링 매니저,
자야람 PVSS(Jayaram PVSS) 수석 엔지니어링 매니저,
케탄 메타(Ketan Mehta) 수석 IP 제품 매니저,
자일링스(Xilinx®)의 오로라(Aurora) 시리얼 통신 코어는 다중 인스턴스들에 걸쳐 공유된 리소스를 제공한다. 비바도 디자인 수트(Vivado® Design Suite)에서 제공되는 IPI(IP Integrator) 툴은 이러한 공유 리소스를 최대한 활용할 수 있도록 해주는 핵심 툴이다.
전자산업은 고속 시리얼 커넥티비티 솔루션 기반으로 빠르게 변화하고 있으며, 병렬 통신 표준은 점차 자리가 좁아지고 있다. 산업 표준 시리얼 프로토콜은 고정된 라인속도와 정의된 레인 폭을 가지고 있어, 기가비트 시리얼 트랜시버의 성능을 충분히 활용하지 못하는 경우가 많다.
오로라는 자일링스의 고속 시리얼 통신 프로토콜로써 여러 산업 분야에서 폭넓은 지지를 받고 있으며, 구현이 너무 복잡하거나 또는 지나치게 리소스-집약적인 경쟁 프로토콜들의 애플리케이션에 전형적으로 사용되고 있다. 오로라는 저비용의 고속 데이터 전송속도와 확장 가능한 IP 솔루션을 제공함으로써 고속 시리얼 데이터 채널을 유연하게 구현할 수 있는 솔루션이다.
라인 속도와 채널 폭을 모두 확장해야 하는 고성능 시스템 및 애플리케이션은 솔루션으로서 오로라를 고려하고 있다. 또한 오로라는 기가비트 데이터 전송 백플레인(backplane)을 갖춘 복수의 FPGA 기반 시스템은 물론, ASIC 디자인에도 적용되고 있다. 오로라의 간단한 프레임 구조와 프로토콜-확장형 플로우 제어 기능은 기존 프로토콜의 데이터를 압축(encapsulate)하는데도 사용할 수 있다. 전기적 요건은 상업용 장비와 호환이 가능하다. 자일링스는 비바도 디자인 수트 IP 카탈로그에서 Aurora 64b66b (64비트-66비트 부호하) 및 Aurora 8b10b (8비트-10비트 부호화) 코어를 제공하고 있다.
비바도 IPI는 복잡한 멀티코어 시스템에서 리소스를 최적화하기 위한 핵심 툴이다. 이러한 점에서 IPI는 특히 ‘공유-로직(Shared-Logic)’ 기능을 통해 Aurora 64b66b 및 Aurora 8b10b 코어의 공유 가능한 리소스를 최대한 활용할 수 있도록 해준다. 편의상, 이 글에서는 Aurora 64b66b IP를 다루기로 하며, Aurora 8b10b 코어 또한 동일한 기법을 적용할 수 있다.
오로라의 공유 가능한 리소스 요약
그림 1은 Aurora 64b66b 코어의 블록 다이어그램을 나타낸 것이다. 강조된 부분은 MMCM(Mixed-Mode Clock Manager), BUFG, IBUFDS와 같은 클럭킹 리소스와 자일링스 7 시리즈 디바이스 기반의 2-레인 디자인을 위해 GT1 및 GT2로 나타낸, GT Common 및 GT 채널과 같은 GT(Gigabit Transceiver) 리소스이다.
그림 1. Aurora 64b66b 코어에서 공유 가능한 리소스(오렌지색 부분)
킨텍스-7(Kintex®-7) FPGA KC705 평가키트(Evaluation Kit)에서 사용된 것처럼, 전형적인 16-레인 Aurora 64b66b 코어를 위한 클럭킹 및 GT 리소스 요건은 표 1에 정리되어 있다.
표 1. Kintex-7 FPGA KC705 평가 키트 상에서 클럭킹 및 GT 리소스 활용도
FPGA의 클럭킹 및 GT 리소스는 선택된 디바이스 및 패키지에 따라 다르다. 종종 다중 IP 코어는 시스템 레벨에서 사용할 수 있는 리소스를 필요로 한다. 따라서 시스템 비용은 물론, 전력소모를 절감할 수 있도록 이러한 귀중한 리소스들을 활용할 수 있도록 최적화하는 것은 필수요건이 되었다.
오로라 리소스 공유
다중 GT-기반 자일링스 코어 전반에 걸쳐 지원되는 공유-로직 기능의 일부처럼, 오로라 코어는 ‘코어의 공유 로직(마스터)’ 또는 ‘예제 디자인의 공유 로직(슬레이브)’ 중 하나로 구성이 가능하다. 두 구성을 조합하면, 클럭킹 및 GT 리소스를 시스템 레벨에서 예시화된 마스터 및 슬레이브에 모두 공유하는 것이 가능하다.
공유-로직 기능이 사용되는 애플리케이션의 경우, 여러 개의 IP를 수작업을 연결하게 되면 오류가 발생할 수 있고, 전반적인 디자인-진입(design-entry) 시간이 증가하게 된다. 이러한 디자인 진입 문제를 해결하기 위한 방법은 툴의 지원을 받는 것이며, 자일링스의 IPI는 이를 명쾌하게 해결할 수 있다.
IPI 툴은 top-level 블록처럼 코어를 가상화하며, 표준 인터페이스 포트 간의 연결은 보다 직관적이고, 인텔리전트하며, 때로는 자동화도 가능하다. 툴 및 IP에 통합되어 있는 적절한 DRC(Design Rule Check)를 통해 잘못된 연결을 하이라이트해주고, 디자이너가 이를 디자인 진입 단계에서 확인할 수 있도록 해준다. Top-level wrapper 파일과 적절한 pin-level I/O 요건 추론은 자동으로 이뤄지며, 시스템 디자이너에게 뛰어난 툴 생산성을 제공한다. 만약 커스텀 서브-블록을 디자인하는 경우라면, 자일링스 애플리케이션 노트 1168(‘Packaging Custom AXI IP for Vivado IP Integrator(XAPP1168)’)에서 언급한 것처럼 해당 디자인의 패키징을 고려할 수도 있으며, IPI에서 서브 블록을 이용할 수도 있다.
오로라의 공유-로직 기능으로 다중 인스턴스에 걸쳐 사용자들이 리소스를 공유할 수 있도록 하는 것은 물론, GT Common, PLL, 클럭킹 및 관련 모듈을 편집할 필요없이 동일한 GT 쿼드에서 즉각적으로 GT 채널을 활용할 수 있도록 해준다. 유일한 제약조건은 ‘공유된’ 코어의 라인 속도가 동일해야 한다는 것이다.(클럭킹 리소스 상에서 패널티를 감수할 수 있다면, 배합도 허용된다.)
전형적인 공유-로직 디자인은 하나의 마스터와 하나 이상의 슬레이브 인스턴스가 쿼드 내에 포함된다. 대부분의 다른 통신 IP와 달리, 오로라는 싱글-쿼드 공유에 제한이 없으며, 오로라 코어를 위한 공유-로직 정의는 지원되는 레인 수에 따라 확장이 가능하다. 오로라의 공유-로직 기능에 기반한 몇 가지 애플리케이션 사례를 소개한다.
복수의 싱글-레인 기반 디자인
단일 FPGA 상의 싱글-레인 기반의 복수 디자인은 채널 결합(bonding)을 필요로 하는 멀티레인 디자인과는 다르다. 직관적으로, 시스템 레벨에 선형적으로 추가되는 싱글-레인 기반의 복수 디자인에 필요한 리소스는 분명하게 이해될 수 있을 것이다. 그렇다면 다른 시나리오들을 살펴보고, 공유-로직 기능이 각 경우에 어떠한 도움을 주는지 알아보자.
우리는 4개의 싱글 레인을 갖춘 디자인으로 시작할 것이다. 이러한 종류의 디자인은 4개의 싱글-레인 오로라 코어를 구성하여 간단하게 구현할 수 있다. 이러한 구현을 실제로 살펴보면, 각 오로라 디자인은 하나의 GT Common 인스턴스를 가지고 있기 때문에, 이 디자인의 배치 및 리소스 활용은 4개의 GT 쿼드 전반으로 확대된다. 이는 리소스-집약적이기 때문에 항상 적절한 솔루션이 되기는 어렵다. 전력 및 리소스 측면에서 뛰어난 배치 및 최적화된 솔루션을 구현하기 위해서는 동일한 GT 쿼드에서 4개의 GT가 선택되어야 한다.
공유-로직 기능을 사용하지 않고, 이러한 요건에 부합하는 디자인을 수작업으로 생성한다면 상당한 노력이 수반될 것이다. 공유-로직 기능을 효과적으로 사용하기 위해, 그림 2에 나타낸 것처럼, 마스터 모드에 하나의 오로라 코어를, 그리고 슬레이브 모드에는 다른 3개의 오로라 코어를 생성해야 한다. 또한 마스터 코어가 슬레이브 코어와의 클럭킹을 제어하기 때문에 코어 리세팅과 같은 추가적인 시스템 레벨 고려사항들을 감안해야 한다. 이러한 구성 및 리소스 최적화는 오로라 코어가 동일한 라인 속도로 구성되어 있는 경우에만 즉각적으로 수행 가능하다. 표 2는 시스템에서 4개의 싱글-레인을 디자인하기 위해 공유-로직 기능을 사용한 경우 얻을 수 있는 혜택을 수치화했다.
그림 2. 하나의 마스터 오로라 코어(좌측)와 3개의 슬레이브를 이용한 공유-로직 디자인
표 2. 4개의 싱글 레인을 갖춘 디자인에서 공유-로직을 통한 리소스 사용 혜택
12개의 GT 채널을 사용하는 디자인
7 시리즈 FPGA의 경우, 남-북 방향의 클럭킹 기반의 GT는 하나의 레퍼런스 클럭 소스로, 이는 중간 쿼드에서 선택되었다면 최대 12개의 GT 채널까지 제공할 수 있다.
그렇다면, 가능한 적은 수의 클럭킹 리소스를 활용해야 하는 12개의 싱글-레인 디자인 요건을 가진 사례를 살펴보자. 그림 2에 보여진 것처럼, 만약 하나의 마스터와 3개의 슬레이브로 구성으로 확장한다면, 클럭킹 리소스를 줄일 수 있다. 하지만 이러한 1+3 구성이 3개의 쿼드로 확장된다면, 이 디자인은 총 6개의 차동-클럭킹 (differential clocking) 리소스가 필요하게 된다. 하지만 싱글-엔디드 INIT_CLK 및 GT 레퍼런스 클럭을 수용할 수 있는 2개의 마스터 디자인을 선택한다면, 좀 더 줄이는 것도 가능하다. 이러한 방법은 시스템에서 차동-클럭 입력 요건을 6개에서 2개로 줄일 수 있으며, IBUFDS/IBUFDS_GTE2 리소스 요건을 줄일 수 있다.(표 3 참조) 이 디자인의 IBUFDS_GTE2 리소스 감소는 실제로 외부 클럭킹 리소스는 물론, 디자인 핀아웃 절감으로까지 이어진다. 유사한 최적화 방법을 MMCM에도 적용할 수 있다.
표 3. 12개의 싱글 레인을 갖춘 디자인에서 공유-로직 기능을 통한 리소스 혜택
3x4 레인 디자인
만약 3x4 레인 디자인 요건이 필요한 경우, 공유-로직 기능을 사용하지 않고, 마스터 모드에서 3x4 레인 오로라 코어를 생성할 수도 있으며, 그런 다음 클럭킹 리소스 활용을 최적화하기 위해 수작업으로 디자인을 생성할 수도 있을 것이다. 그렇다면 즉각적으로 동일한 결과를 달성할 수 있다면 어떻게 할 것인가? 그림 3에 나타낸 것처럼, 하나의 마스터 코어와 2개의 슬레이브 코어를 원하는 형식으로 바로 할 수 있다.
그림 3. 3개의 연속 쿼드 기반의 4-레인 오로라 디자인을 위한
하나의 마스터와 2-슬레이브 컨피규레이션
대형(16개 이상의) 싱글-레인 오로라 디자인의 크기 문제를 고려한다면, 공유 로직의 필요성은 더욱 더 중요해진다. 간혹 48개의 싱글-레인 기반의 독립적인 듀플렉스 (duplex) 링크를 필요로 하는 대규모 디자인이 있을 수 있다. 오로라의 허용 가능한 싱글-레인 링크의 수는 선택된 디바이스에서 이용 가능한 GT 리소스 수에 따라서만 제한된다. 따라서 이 경우, 공유-로직 기능을 효과적으로 사용하지 않고, 이러한 시스템 디자인을 실현하기는 어렵다.
표 4. 3x4 레인 디자인을 위한 최적화된 레인 선택
이 디자인은 12 쿼드까지 확산되기 때문에, 2*12 차동-클럭킹 리소스가 필요하게 되며, 이는 보드 디자인 측면에서 상당히 어려운 작업이 될 수 있다. 12개의 싱글-레인 디자인 사례에서 언급한 기법을 사용함으로써, 시스템 전반의 차동 클럭 및 MMCM 요건을 줄일 수 있다.(표 5 참조)
비대칭 레인 및 또 다른 커스텀 최적화
비디오 프로젝터와 같은 애플리케이션에서, 메인스트림 (mainstream) 데이터는 높은 처리량으로 한 방향에서 처리되며, 낮은 처리량의 비정규 채널(Back Channel)은 정보를 제어하거나 보조 전송을 위해 사용된다. 이러한 애플리케이션에서 완벽한 기능의 듀플렉스 링크를 갖추게 된다면, 대역폭 사용량을 훨씬 더 줄일 수 있으며, 이를 통해 시스템 디자인의 ROI 비용을 낮출 수 있게 된다. 이러한 형태의 문제에 적합한 솔루션은 그림 4에 나타낸 것처럼, GT 리소스 활용을 최적화한 비대칭 링크 폭이 해결책이 될 수 있으며, 한 방향의 데이터 플로우(보다 높은 처리량)의 레인 수는 다른 방향(낮은 처리량)의 레인 수보다 더 높아질 수 있다.
그림 4. 오로라를 이용한 링크 간의 비대칭 데이터 전송 가능
현재 오로라 코어에서 이용 가능한 데이터 플로우 모드(심플렉스/듀플렉스)로는, 동일한 수의 TX 및 RX 레인으로만 코어를 구성하는 것이 가능하다. 두 방향으로 다른 수의 레인을 만들기 위해서는 각 방향을 위한 2개의 오로라 심플렉스 코어를 생성해야 한다. 7 시리즈 FPGA에서 이러한 종류의 비대칭 레인 디자인을 구현하는 방법은 자일링스 애플리케이션 노트 - ‘Asymmetric Lane Design with Aurora 64B/66B IP Core’(XAPP1227)에서 확인할 수 있다.
또 다른 유용한 디자인 전략은 BUFG 리소스 최적화이다. 동일하거나, 또는 서로 다른 라인 속도로 동작하는 다중 오로라 코어를 구현하는 시스템 디자이너는 디바이스에 특화된 클럭킹 요건 및 제한사항을 알고 있어야 한다. 수많은 오로라 링크를 구현하기 위해서는 각각의 링크에 대한 클럭도 생성해야 하며, 이러한 클럭킹 리소스를 보전하는 것은 시스템을 보다 비용 효과적으로 구현할 수 있도록 해준다. 만약 시스템 디자인이 여러 블록을 가지고 있고, 클럭킹 리소스가 부족하다면, BUFG를 BUFR/BUFH로 대체하는 것도 고려할 수 있다. 권고사항이기는 하지만, 동일한 버퍼 타입으로 GT 코어의 유저 클럭 및 TX 경로를 모두 드라이브할 수 있다.
7 시리즈 오로라 코어는 부가적인 DRP(Dynamic Reconfiguration Port) 클럭 입력이 필요한 반면, 하나의 BUFG 만을 사용해야 한다. 오로라의 프리-러닝(Free-Running) 클럭 주파수를 허용 가능한 DRP 클럭 범위 내에서 선택했다면, 오로라에서 이용 가능한 출력 프리-러닝 클럭은 재사용이 가능하고, DRP 클럭과 다시 연결할 수 있다. 이를 통해 생성된 디자인의 BUFG 수를 절감할 수 있다.
다중 오로라 디자인에서 라인 속도를 선택할 때, 링크 전반에 걸쳐 공유 및 클럭 파생이 보다 용이하도록 라인 속도가 정배수가 되었다면, 클럭킹 리소스를 공유할 수 있다는 점에 주목하자. 공유-로직 기능이 하모닉 라인 속도를 확장했다면, 몇몇 외부의 클럭 분배기에 디자인함으로써 슬레이브 오로라 코어를 위해 필요한 입력 주파수를 생성할 수 있다.
표 5. 48개의 싱글-레인 디자인을 위한 공유-로직 기능의 리소스 혜택
미래의 가능성
오로라의 유연성은 다양한 시스템 구성 및 애플리케이션을 구현할 수 있는 새로운 가능성을 열었다. 자일링스의 비바도 IPI와 같은 강력한 툴의 지원으로 디자인 엔트리 레벨의 생산성 및 시스템 레벨의 리소스 공유가 실현됨으로써 올 프로그래머블(All Programmable) 애플리케이션 분야의 혁신이 가속화되고 있다. 자일링스의 울트라스케일(UltraScale™) 아키텍처 기반의 디바이스들은 보다 많은 GT 채널과 향상된 GT 라인 속도를 갖추고 있으며, 이를 통해 리소스 활용의 가능성 및 효용성은 훨씬 더 높아지고 있다.
오로라 코어에 대한 평가는 IP 카탈로그와 IPI, 그리고 오로라 제품정보 웹 페이지에서 확인할 수 있다.
- 제품스펙 :
- http://www.xilinx.com/products/design_resources/conn_central/grouping/aurora.htm
- 태그 :
- 비바도, IPI, UltraScale
- 적용분야 :
- High Performance Computing
- 관련제품 :
- Kintex-7