Technical Article
제품 및 Tools
자일링스 Zynq SoC로 클라우드 컴퓨팅 가속
자일링스 Zynq SoC로 클라우드 컴퓨팅 가속
2014-04-02
독보적인 새로운 리컨피규러블 하드웨어 가속기로 맵리듀스(MapReduce) 프로그래밍 프레임워크 기반 애플리케이션의 프로세싱 속도 향상.
글/ 크리스토포로스 카크리스(Christoforos Kachris) DUTH(Democritus University of Thrace) 연구원, 게오르기오스 시라쿨리스(Georgios Sirakoulis) DUTH 교수, 디미트리오스 수드리스(Dimitrios Soudris) NTUA(National Technical University of Athens) 교수
비디오 스트리밍, 소셜 네트워크, 클라우드 컴퓨팅과 같은 웹 애플리케이션의 등장으로 수천 개의 서버 호스팅이 가능한 웨어하우스-규모의 데이터 센터에 대한 필요성이 대두되고 있다. 데이터 센터 및 다른 컴퓨터 클러스터에서 대규모 데이터 세트를 프로세싱하기 위한 메인 프로그래밍 프레임네트워크 중 하나는 맵리듀스(MapReduce)이다.[1] 맵리듀스는 수많은 노드를 이용해 대규모 데이터 세트를 프로세싱하기 위한 프로그래밍 모델이다. 이는 ‘맵(Map)’과 리듀스(Reduce)’ 기능으로 구성되며, 맵리듀스 스케쥴러가 작업을 프로세서로 분산시킨다.
맵리듀스 프레임워크의 주요 장점 중 하나는 각기 다른 타입의 프로세서로 구성된 이종 클러스터에서 호스팅이 가능하다는 것이다. 대부분의 데이터 센터는 인텔의 제온(Xeon)이나 AMD의 옵테론(Opteron), IBM의 파워 프로세서(Power Processor)와 같은 고성능의 범용 디바이스에 기반하고 있다. 하지만 이러한 프로세서는 애플리케이션이 연산 집약적이지 않고 I/O 집약적인 경우라 하더라도 전력소모가 매우 크다.
데이터 센터의 전력소모를 줄이기 위해, 최근 마이크로서버가 대안 플랫폼으로 주목받고 있다. 이러한 저렴한 서버는 일반적으로 임베디드 시스템에 사용되는 것(예를 들어, ARM® 프로세서)과 같은 에너지 효율적인 프로세서에 기반하고 있다. 마이크로서버는 주로 고성능 프로세서 보다는 노드 간의 충분한 I/O로 개별 서버의 가장 큰 혜택을 얻을 수 있는 경량의 병렬 애플리케이션을 겨냥하고 있다. 마이크로서버 방식의 장점은 구입 비용을 절감하고, 풋프린트 및 특정 형태의 애플리케이션을 위한 높은 에너지 효율을 줄인다는 것이다.
지난 몇 년 동안 시마이크로(SeaMicro), 칼세다(Calxeda)와 같은 여러 공급업체들이 임베디드 프로세서에 기반한 마이크로서버를 개발했다. 그러나 맵리듀스 프레임워크는 임베디드 프로세서에서 여러 리소스를 할당함으로써 이러한 플랫폼에서 구동하는 클라우드 컴퓨팅 애플리케이션의 전반적인 성능을 감소시킨다.
이러한 문제를 극복하기 위해 우리의 개발 팀은 완벽한 프로그래머블 플랫폼에 ARM 코어를 효율적으로 통합할 수 있는 맵리듀스 프레임워크를 위한 하드웨어 가속장치를 개발했다. 이러한 계획을 평가하고 실현하기 위해, 듀얼-코어 Cortex™-A9 프로세서를 하드 코어로 통합한 자일링스(Xilinx®) Zynq®-7000 올 프로그래머블(All Programmable) SoC를 채택했다.
맵리듀스 하드웨어 가속장치
맵리듀스 가속장치는 리듀스(Reduce) 작업을 효율적으로 구현할 수 있게 해준다. 이 장치의 주 역할은 모든 프로세서의 중간 키/값(Key/Value) 쌍을 병합하고, 새로운 키 삽입이나 키/값 쌍의 업데이트(누적)를 위한 고속 액세스를 제공하는 것이다. 개발 팀은 공유 버스를 통해 멀티코어 프로세서를 증대시킬 수 있는 코프로세서처럼 맵리듀스 가속기를 구현했다. 멀티코어 SoC 내 이 가속기의 블록 다이어그램은 그림 1에 나타내었다.
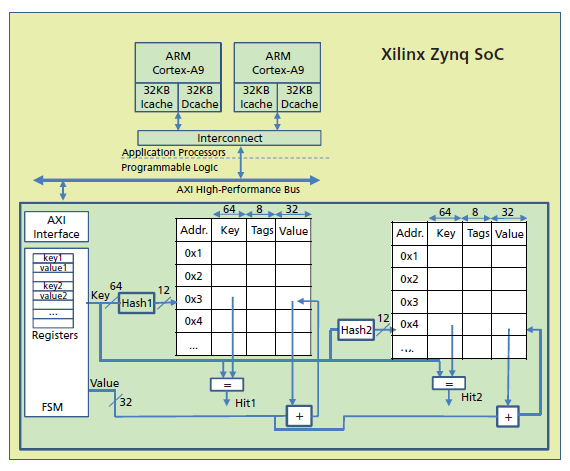
그림 1. 맵리듀스 하드웨어 가속기의 블록 다이어그램
그림에 나타낸 것처럼, 우리는 두 개의 ARM Cortex-A9 코어를 갖춘 Zynq SoC 내에 이 하드웨어 가속 장치를 통합했다. 각 코어는 자체 명령어 및 데이터-레벨 캐시를 가지고 있으며, 공유 인터커넥션 네트워크를 이용해 각각 주변기기와 통신한다. 가속기는 인터커넥션 네트워크에 부속된 고성능 버스를 통해 프로세서와 통신한다. 프로세서는 가속기의 특정 레지스터에 액세스함으로써 맵리듀스 가속기로 업데이트되어야 하는 키 및 값을 산출한다. 맵(Map) 작업이 끝난 후, 가속기는 모든 키를 위한 값을 이미 누적하게 된다. 프로세서는 키만 가속기에 보내고, 레지스터에서 최종 값을 판독함으로써 키의 최종 값을 불러온다. 이러한 방법으로 고안된 아키텍처는 업데이트에 필요한 키/값 쌍을 포함하고 있는 공유 버스로 논블록킹 트랜잭션을 전송함으로써 맵리듀스 프로세싱을 가속할 수 있다.
프로그래밍 프레임네트워크
그림 2는 하드웨어 가속기를 이용한 맵리듀스 애플리케이션의 프로그래밍 프레임워크를 보여준다. 원래의 코드에서, 맵 단계는 키/값 쌍을 도출하고, 리듀스 단계에서는 여러 CPU 클럭 사이클을 소모하여 이 키를 검색하고, 새로운 값을 업데이트(누적)한다. 반면 맵리듀스 기속기를 이용하는 경우, 맵 단계에서 키/값 쌍 만을 도출하면, 맵리듀스 가속기가 모든 키/값 쌍을 병합하고, 관련된 엔트리를 업데이트하기 때문에 리듀스 기능을 제거할 수 있다.

그림 2. 프로그래밍 프레임워크
리눅스 기반에서 구동하는 애플리케이션 레벨에서 하드웨어 가속기까지의 통신은 메모리 맵(mmap) 시스템 호출을 이용해 이뤄진다. 이 mmap 시스템 호출은 사용자가 메모리를 매핑하는 동안 제공되는 속성에 기반하여 읽고 쓸 수 있도록 유저 레이어에 특정 커널 메모리 영역을 매핑하는데 사용할 수 있다.
우리는 이러한 레지스터에 액세스하고, 키/값 요소 업데이트를 직렬화하기 위해 제어 유닛을 사용한다. 키/값 쌍은 애플리케이션 요건에 따라 컨피규레이션이 가능한 메모리 유닛에 저장된다. 메모리 블록은 키, 값, 그리고 태그처럼 사용되는 약간의 비트를 포함하고 있다. 이러한 태그는 메모리 라인이 비어있는지, 그리고 유효한지 아닌지를 나타낸다. 키에 대한 색인을 가속하기 위해 해쉬 모듈(Hash Module)은 초기의 키를 메모리 블록에 어드레스할 수 있도록 변환한다.
현재 컨피규레이션에서 우리는 2K 키/값 쌍을 호스트하기 위해 메모리 구조를 디자인했다. 각 키는 64bit의 길이(8 문자열)가 될 수 있고, 값은 32bit 길이가 될 수 있다. 메모리 구조의 총 사이즈는 2K x 104bit이다. 첫 번째 64bit에는 해쉬 기능을 이용하여 실행여부를 비교하기 위해 키를 저장했다. 다음 8bit는 태그를 위해 사용되었으며, 그 다음 32bit에는 값을 저장했다. 현재 컨피규레이션에서 키의 최대값은 64bit이고, 해쉬 기능은 키(64bit)를 메모리 어드레스(12bit) 안에 매핑하기 위해 사용된다.
쿠쿠 해싱(CUCKOO HASHING)
해시 기능은 키 색인을 가속시킬 수 있지만, 2개의 각기 다른 키가 동일한 해시 값을 가지고 있는 경우 충돌이 발생할 수 있다. 이러한 문제를 해결하기 위해 해시 충돌을 해소하는 최상의 방법인 쿠쿠 해싱(Cuckoo Hashing)을 선택했다. 쿠쿠 해싱[2]은 해시 기능을 하나 만 사용하는 것이 아니라 2개의 해시 기능을 사용한다. 새로운 엔트리가 삽입되고 나면, 이는 첫 번째 해시 키의 위치에 저장된다. 만약 이 위치가 점유된 상태라면, 기존 엔트리는 두 번째 해시 어드레스로 이동되고, 비어있는 슬롯이 발견될 때까지 이 절차가 반복된다. 이 알고리즘은 일관된 색인 시간 O(1)(색인은 해시 테이블에서 2개의 위치 검사가 필요하다.)을 제공하는 반면, 삽입 시간은 캐시 사이즈 O(n)에 따라 달라진다. 만약 이 절차가 무한 루프에 돌입하게 되면, 해시 테이블이 재구성된다.
쿠쿠 해싱 알고리즘은 각 해시 기능 및 각 사이즈 r을 위한 T1 및 T2, 2개의 테이블을 이용해 구현될 수 있다. 이러한 각각의 테이블은 T1 및 T2 어드레스를 생성하기 위해 각각 h1, h2의 서로 다른 해시 기능을 사용한다. 모든 요소 x는 해시 기능 h1이나 h2를 각각 사용하여 T1이나 T2 중 하나에 저장되며, 이는 T1[h1(x)] 혹은 T2[h2(x)]가 된다. 따라서 색인이 복잡하지 않다. 색인해야 하는 각각의 요소 x를 위해 우리는 해시 기능 h1 및 h2를 각각 사용하는 테이블 T1 및 T2에서 2개의 가능한 위치를 확인하기만 하면 된다.
요소 x를 삽입하기 위해서, T1[h1(x)]가 비었는지 확인한 다음, 이 위치에 요소를 저장한다. 만약 비어있지 않다면, 이미 T1[h1(x)]에 있는 요소 y를 x로 대체한다. 그런 다음 T2[h2(y)]가 비어 있는지 확인한다. 만약 비었다면, 이 위치에 요소를 저장한다. 만약 그렇지 않다면, T2[h2(y)]에 있는 요소 z를 y로 대체한다. 다시 T1[h1(z)]에 z를 배치할 수 있도록 한 다음, 계속해서 빈 위치를 찾을 때까지 반복한다.
원래의 쿠쿠 해싱 문서에 따르면[2], 시도된 특정 횟수 내에 비어있는 위치가 발견되지 않으면, 제안된 솔루션은 테이블의 모든 요소를 거의 그대로 반복하게 된다. 현재 구현된 소프트웨어는 동작이 이러한 루프에 진입할 때마다 기능 호출을 중단시키거나 돌려보낸다. 그런 다음 기능 호출은 재해싱을 시작하게 하거나, 원래 코드의 소프트웨어 메모리 구조에 특정 키를 추가하게 할 수도 있다.
그림 1에 나타낸 것처럼, 우리는 맵리듀스 가속기를 위한 쿠쿠 해싱을 구현했다. 2개의 테이블을 위한 엔트리를 저장하기 위해 2개의 블록 RAM을 사용했다. 이러한 BRAM은 키와 값, 태그를 저장한다. 태그 필드에 있는 하나의 bit는 특정 열이 유효한지 아닌지를 나타내기 위해 사용된다. 2개의 해시 기능은 BRAM을 위한 어드레스에 키를 매핑하는 간단한 XOR 기능을 기반으로 사용되었다. 액세스할 때마다 BRAM이 요구되며, 해시 테이블은 어드레스를 생성하는데 사용되고, 그런 다음 2개의 비교기가 BRAM에 적합한지의 여부를 나타내게 된다.(즉, 이 키는 RAM에 있는 키와 동일하며, 유효한 비트는 1이다.) 제어 유닛은 메모리에 액세스하는 것을 조정한다. 우리는 쿠쿠 해싱을 실행하는 FSM(Finite State Machine)처럼 제어 유닛을 구현했다.
성능 평가
우리는 계획한 아키텍처를 Zynq SoC에 구현했으며, 리눅스 3 기반의 임베디드 ARM 코어에 특별히 피닉스(Phonnix) 맵리듀스 프레임워크를 매핑했다. 이는 프로세서가 키/값 쌍을 업데이트해야 할 때마다 특정 기능 호출을 통해 정보를 전송한다. 시스템의 성능 평가를 위해 피닉스 프레임워크의 3가지 애플리케이션을 사용했으며, 이러한 워드카운트(WordCount), 선형회귀분석(Linear Regression), 히스토그램(Histogram)에 대해 하드웨어 가속기를 활용하여 동작을 수정했다.
계획했던 구조는 컨피규러블하고 애플리케이션 요건에 따라 조정이 가능해야 한다. 피닉스 맵리듀스 프레임워크 애플리케이션의 성능 평가를 위해 4K 메모리 유닛(4,096 키/값 쌍을 저장할 수 있음: 각 BRAM에 2K)을 포함하도록 가속기를 컨피규레이션했다. 각 키의 최대 사이즈는 8byte이다.
표 1은 맵리듀스 가속기의 프로그래머블 로직 리소스를 보여주고 있다. 나타낸 것처럼, 가속기는 기본적으로 메모리-집약적인 반면, 제어 유닛은 FSM(Finite State Machine)에 사용되며, 해시 기능은 디바이스에서 적은 부분만을 차지한다.
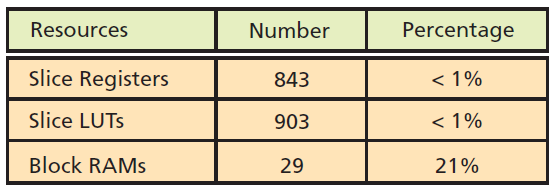
표 1. 프로그래머블 로직 리소스 할당
그림 3은 원래 애플리케이션의 실행 시간과 맵리듀스 가속기를 이용한 애플리케이션의 실행시간을 비교한 것이다. 이러한 측정값은 모두 자일링스 Zynq SoC 디자인을 기반으로 했다.
맵리듀스 애플리케이션 실행시간
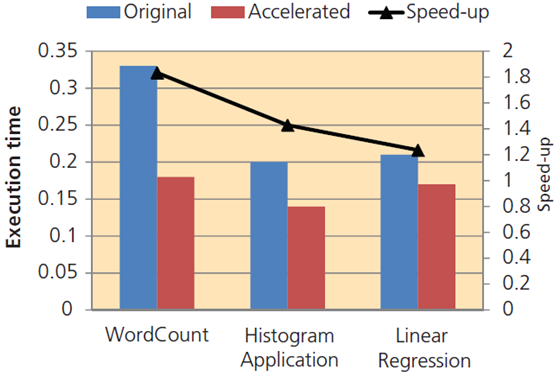
그림 3. 전체 시스템 속도는 애플리케이션에 따라 1.23x에서 1.8x까지 높아졌다.
워드카운트의 경우, 원래의 애플리케이션에서 맵 작업은 워드를 식별하고 이를 리듀스 작업으로 내보낸다. 이 작업은 모든 키/값 쌍을 모으고, 각 키를 위한 값을 축적하게 된다. 가속기의 경우, 맵 작업에서 워드를 식별한 다음, 이 데이터를 고성능 AXI 버스를 통해 맵리듀스 가속장치로 전달한다. 키/값 쌍은 레지스터(각 프로세서마다 다름)에 저장된 다음, 가속기는 메모리 구조에 액세스함으로써 각 키를 위한 값을 모은다.
프로세서 오프로드
실행시간 단축은 리듀스 작업이 키/값 테이블을 먼저 로드한 다음, 필요한 키를 테이블을 통해 검색해야 하는 원래의 코드에서 기인한다. 값이 축적된 이후, 리듀스 작업은 키를 다시 메모리에 저장해야 한다. 우리는 맵리듀스 가속기를 활용함으로써 이 작업을 프로세서에서 오프로드할 수 있었기 때문에 전체 실행시간을 단축할 수 있었다. 쿠쿠 해싱(O(1))은 가속기에서 키 검색시간이 그대로 유지된 반면, 프로세서는 키/값 쌍이 업데이트되는 동안 차단되지 않았다.
그림 3에 나타낸 것처럼, 시스템의 전체 속도가 1.23배에서 1.8배까지 높아졌다. 속도향상은 각 애플리케이션의 특성에 따라 달라진다. 매핑 기능이 보다 복잡한 경우, 맵리듀스 가속기의 속도향상은 적게 나타났다. 전반적인 실행시간이 적게 할당되는 보다 간단한 매핑 기능을 가진 애플리케이션에서는 속도가 크게 향상되었으며, 이는 전체 실행시간의 많은 부분이 맵 및 리듀스 기능 간의 통신에 사용되기 때문이다. 따라서 이 경우, 맵리듀스 가속기는 훨씬 뛰어난 가속을 제공할 수 있다. 또한 맵리듀스 가속기는 프로세서에서 보다 적은 새로운 스레드를 생성하게 되며, 보다 적게 컨텍스트 전환을 하기 때문에 실행시간을 줄일 수 있다. 예를 들어, 워드카운트의 경우, 평균 컨텍스트 전환 수는 88에서 60까지 떨어진다.
맵리듀스 프레임워크는 멀티코어 SoC 및 클라우드 컴퓨팅 애플리케이션을 위한 프로그래밍 프레임워크로 폭넓게 사용이 가능하다. 우리가 제안하는 하드웨어 가속기는 자일링스 Zynq SoC와 같은 멀티코어 SoC 플랫폼 및 맵리듀스 프레임워크 기반 클라우드 컴퓨팅 애플리케이션에서 이러한 애플리케션의 리듀스 작업을 가속함으로써 전체 실행시간을 줄이는데 사용할 수 있다. Zynq SoC 플랫폼 기반 클라우드 컴퓨팅 가속에 대한 보다 자세한 정보는 이 글의 저자인 크리스토포로스 카크리스(Christoforos Kachris, ckachris@ee.duth.gr)에게 연락을 하거나 웹사이트 www.green-center.weebly.com에서 확인할 수 있다.
글/ 크리스토포로스 카크리스(Christoforos Kachris) DUTH(Democritus University of Thrace) 연구원, 게오르기오스 시라쿨리스(Georgios Sirakoulis) DUTH 교수, 디미트리오스 수드리스(Dimitrios Soudris) NTUA(National Technical University of Athens) 교수
비디오 스트리밍, 소셜 네트워크, 클라우드 컴퓨팅과 같은 웹 애플리케이션의 등장으로 수천 개의 서버 호스팅이 가능한 웨어하우스-규모의 데이터 센터에 대한 필요성이 대두되고 있다. 데이터 센터 및 다른 컴퓨터 클러스터에서 대규모 데이터 세트를 프로세싱하기 위한 메인 프로그래밍 프레임네트워크 중 하나는 맵리듀스(MapReduce)이다.[1] 맵리듀스는 수많은 노드를 이용해 대규모 데이터 세트를 프로세싱하기 위한 프로그래밍 모델이다. 이는 ‘맵(Map)’과 리듀스(Reduce)’ 기능으로 구성되며, 맵리듀스 스케쥴러가 작업을 프로세서로 분산시킨다.
맵리듀스 프레임워크의 주요 장점 중 하나는 각기 다른 타입의 프로세서로 구성된 이종 클러스터에서 호스팅이 가능하다는 것이다. 대부분의 데이터 센터는 인텔의 제온(Xeon)이나 AMD의 옵테론(Opteron), IBM의 파워 프로세서(Power Processor)와 같은 고성능의 범용 디바이스에 기반하고 있다. 하지만 이러한 프로세서는 애플리케이션이 연산 집약적이지 않고 I/O 집약적인 경우라 하더라도 전력소모가 매우 크다.
데이터 센터의 전력소모를 줄이기 위해, 최근 마이크로서버가 대안 플랫폼으로 주목받고 있다. 이러한 저렴한 서버는 일반적으로 임베디드 시스템에 사용되는 것(예를 들어, ARM® 프로세서)과 같은 에너지 효율적인 프로세서에 기반하고 있다. 마이크로서버는 주로 고성능 프로세서 보다는 노드 간의 충분한 I/O로 개별 서버의 가장 큰 혜택을 얻을 수 있는 경량의 병렬 애플리케이션을 겨냥하고 있다. 마이크로서버 방식의 장점은 구입 비용을 절감하고, 풋프린트 및 특정 형태의 애플리케이션을 위한 높은 에너지 효율을 줄인다는 것이다.
지난 몇 년 동안 시마이크로(SeaMicro), 칼세다(Calxeda)와 같은 여러 공급업체들이 임베디드 프로세서에 기반한 마이크로서버를 개발했다. 그러나 맵리듀스 프레임워크는 임베디드 프로세서에서 여러 리소스를 할당함으로써 이러한 플랫폼에서 구동하는 클라우드 컴퓨팅 애플리케이션의 전반적인 성능을 감소시킨다.
이러한 문제를 극복하기 위해 우리의 개발 팀은 완벽한 프로그래머블 플랫폼에 ARM 코어를 효율적으로 통합할 수 있는 맵리듀스 프레임워크를 위한 하드웨어 가속장치를 개발했다. 이러한 계획을 평가하고 실현하기 위해, 듀얼-코어 Cortex™-A9 프로세서를 하드 코어로 통합한 자일링스(Xilinx®) Zynq®-7000 올 프로그래머블(All Programmable) SoC를 채택했다.
맵리듀스 하드웨어 가속장치
맵리듀스 가속장치는 리듀스(Reduce) 작업을 효율적으로 구현할 수 있게 해준다. 이 장치의 주 역할은 모든 프로세서의 중간 키/값(Key/Value) 쌍을 병합하고, 새로운 키 삽입이나 키/값 쌍의 업데이트(누적)를 위한 고속 액세스를 제공하는 것이다. 개발 팀은 공유 버스를 통해 멀티코어 프로세서를 증대시킬 수 있는 코프로세서처럼 맵리듀스 가속기를 구현했다. 멀티코어 SoC 내 이 가속기의 블록 다이어그램은 그림 1에 나타내었다.
그림 1. 맵리듀스 하드웨어 가속기의 블록 다이어그램
그림에 나타낸 것처럼, 우리는 두 개의 ARM Cortex-A9 코어를 갖춘 Zynq SoC 내에 이 하드웨어 가속 장치를 통합했다. 각 코어는 자체 명령어 및 데이터-레벨 캐시를 가지고 있으며, 공유 인터커넥션 네트워크를 이용해 각각 주변기기와 통신한다. 가속기는 인터커넥션 네트워크에 부속된 고성능 버스를 통해 프로세서와 통신한다. 프로세서는 가속기의 특정 레지스터에 액세스함으로써 맵리듀스 가속기로 업데이트되어야 하는 키 및 값을 산출한다. 맵(Map) 작업이 끝난 후, 가속기는 모든 키를 위한 값을 이미 누적하게 된다. 프로세서는 키만 가속기에 보내고, 레지스터에서 최종 값을 판독함으로써 키의 최종 값을 불러온다. 이러한 방법으로 고안된 아키텍처는 업데이트에 필요한 키/값 쌍을 포함하고 있는 공유 버스로 논블록킹 트랜잭션을 전송함으로써 맵리듀스 프로세싱을 가속할 수 있다.
프로그래밍 프레임네트워크
그림 2는 하드웨어 가속기를 이용한 맵리듀스 애플리케이션의 프로그래밍 프레임워크를 보여준다. 원래의 코드에서, 맵 단계는 키/값 쌍을 도출하고, 리듀스 단계에서는 여러 CPU 클럭 사이클을 소모하여 이 키를 검색하고, 새로운 값을 업데이트(누적)한다. 반면 맵리듀스 기속기를 이용하는 경우, 맵 단계에서 키/값 쌍 만을 도출하면, 맵리듀스 가속기가 모든 키/값 쌍을 병합하고, 관련된 엔트리를 업데이트하기 때문에 리듀스 기능을 제거할 수 있다.
그림 2. 프로그래밍 프레임워크
리눅스 기반에서 구동하는 애플리케이션 레벨에서 하드웨어 가속기까지의 통신은 메모리 맵(mmap) 시스템 호출을 이용해 이뤄진다. 이 mmap 시스템 호출은 사용자가 메모리를 매핑하는 동안 제공되는 속성에 기반하여 읽고 쓸 수 있도록 유저 레이어에 특정 커널 메모리 영역을 매핑하는데 사용할 수 있다.
우리는 이러한 레지스터에 액세스하고, 키/값 요소 업데이트를 직렬화하기 위해 제어 유닛을 사용한다. 키/값 쌍은 애플리케이션 요건에 따라 컨피규레이션이 가능한 메모리 유닛에 저장된다. 메모리 블록은 키, 값, 그리고 태그처럼 사용되는 약간의 비트를 포함하고 있다. 이러한 태그는 메모리 라인이 비어있는지, 그리고 유효한지 아닌지를 나타낸다. 키에 대한 색인을 가속하기 위해 해쉬 모듈(Hash Module)은 초기의 키를 메모리 블록에 어드레스할 수 있도록 변환한다.
현재 컨피규레이션에서 우리는 2K 키/값 쌍을 호스트하기 위해 메모리 구조를 디자인했다. 각 키는 64bit의 길이(8 문자열)가 될 수 있고, 값은 32bit 길이가 될 수 있다. 메모리 구조의 총 사이즈는 2K x 104bit이다. 첫 번째 64bit에는 해쉬 기능을 이용하여 실행여부를 비교하기 위해 키를 저장했다. 다음 8bit는 태그를 위해 사용되었으며, 그 다음 32bit에는 값을 저장했다. 현재 컨피규레이션에서 키의 최대값은 64bit이고, 해쉬 기능은 키(64bit)를 메모리 어드레스(12bit) 안에 매핑하기 위해 사용된다.
쿠쿠 해싱(CUCKOO HASHING)
해시 기능은 키 색인을 가속시킬 수 있지만, 2개의 각기 다른 키가 동일한 해시 값을 가지고 있는 경우 충돌이 발생할 수 있다. 이러한 문제를 해결하기 위해 해시 충돌을 해소하는 최상의 방법인 쿠쿠 해싱(Cuckoo Hashing)을 선택했다. 쿠쿠 해싱[2]은 해시 기능을 하나 만 사용하는 것이 아니라 2개의 해시 기능을 사용한다. 새로운 엔트리가 삽입되고 나면, 이는 첫 번째 해시 키의 위치에 저장된다. 만약 이 위치가 점유된 상태라면, 기존 엔트리는 두 번째 해시 어드레스로 이동되고, 비어있는 슬롯이 발견될 때까지 이 절차가 반복된다. 이 알고리즘은 일관된 색인 시간 O(1)(색인은 해시 테이블에서 2개의 위치 검사가 필요하다.)을 제공하는 반면, 삽입 시간은 캐시 사이즈 O(n)에 따라 달라진다. 만약 이 절차가 무한 루프에 돌입하게 되면, 해시 테이블이 재구성된다.
쿠쿠 해싱 알고리즘은 각 해시 기능 및 각 사이즈 r을 위한 T1 및 T2, 2개의 테이블을 이용해 구현될 수 있다. 이러한 각각의 테이블은 T1 및 T2 어드레스를 생성하기 위해 각각 h1, h2의 서로 다른 해시 기능을 사용한다. 모든 요소 x는 해시 기능 h1이나 h2를 각각 사용하여 T1이나 T2 중 하나에 저장되며, 이는 T1[h1(x)] 혹은 T2[h2(x)]가 된다. 따라서 색인이 복잡하지 않다. 색인해야 하는 각각의 요소 x를 위해 우리는 해시 기능 h1 및 h2를 각각 사용하는 테이블 T1 및 T2에서 2개의 가능한 위치를 확인하기만 하면 된다.
요소 x를 삽입하기 위해서, T1[h1(x)]가 비었는지 확인한 다음, 이 위치에 요소를 저장한다. 만약 비어있지 않다면, 이미 T1[h1(x)]에 있는 요소 y를 x로 대체한다. 그런 다음 T2[h2(y)]가 비어 있는지 확인한다. 만약 비었다면, 이 위치에 요소를 저장한다. 만약 그렇지 않다면, T2[h2(y)]에 있는 요소 z를 y로 대체한다. 다시 T1[h1(z)]에 z를 배치할 수 있도록 한 다음, 계속해서 빈 위치를 찾을 때까지 반복한다.
원래의 쿠쿠 해싱 문서에 따르면[2], 시도된 특정 횟수 내에 비어있는 위치가 발견되지 않으면, 제안된 솔루션은 테이블의 모든 요소를 거의 그대로 반복하게 된다. 현재 구현된 소프트웨어는 동작이 이러한 루프에 진입할 때마다 기능 호출을 중단시키거나 돌려보낸다. 그런 다음 기능 호출은 재해싱을 시작하게 하거나, 원래 코드의 소프트웨어 메모리 구조에 특정 키를 추가하게 할 수도 있다.
그림 1에 나타낸 것처럼, 우리는 맵리듀스 가속기를 위한 쿠쿠 해싱을 구현했다. 2개의 테이블을 위한 엔트리를 저장하기 위해 2개의 블록 RAM을 사용했다. 이러한 BRAM은 키와 값, 태그를 저장한다. 태그 필드에 있는 하나의 bit는 특정 열이 유효한지 아닌지를 나타내기 위해 사용된다. 2개의 해시 기능은 BRAM을 위한 어드레스에 키를 매핑하는 간단한 XOR 기능을 기반으로 사용되었다. 액세스할 때마다 BRAM이 요구되며, 해시 테이블은 어드레스를 생성하는데 사용되고, 그런 다음 2개의 비교기가 BRAM에 적합한지의 여부를 나타내게 된다.(즉, 이 키는 RAM에 있는 키와 동일하며, 유효한 비트는 1이다.) 제어 유닛은 메모리에 액세스하는 것을 조정한다. 우리는 쿠쿠 해싱을 실행하는 FSM(Finite State Machine)처럼 제어 유닛을 구현했다.
성능 평가
우리는 계획한 아키텍처를 Zynq SoC에 구현했으며, 리눅스 3 기반의 임베디드 ARM 코어에 특별히 피닉스(Phonnix) 맵리듀스 프레임워크를 매핑했다. 이는 프로세서가 키/값 쌍을 업데이트해야 할 때마다 특정 기능 호출을 통해 정보를 전송한다. 시스템의 성능 평가를 위해 피닉스 프레임워크의 3가지 애플리케이션을 사용했으며, 이러한 워드카운트(WordCount), 선형회귀분석(Linear Regression), 히스토그램(Histogram)에 대해 하드웨어 가속기를 활용하여 동작을 수정했다.
계획했던 구조는 컨피규러블하고 애플리케이션 요건에 따라 조정이 가능해야 한다. 피닉스 맵리듀스 프레임워크 애플리케이션의 성능 평가를 위해 4K 메모리 유닛(4,096 키/값 쌍을 저장할 수 있음: 각 BRAM에 2K)을 포함하도록 가속기를 컨피규레이션했다. 각 키의 최대 사이즈는 8byte이다.
표 1은 맵리듀스 가속기의 프로그래머블 로직 리소스를 보여주고 있다. 나타낸 것처럼, 가속기는 기본적으로 메모리-집약적인 반면, 제어 유닛은 FSM(Finite State Machine)에 사용되며, 해시 기능은 디바이스에서 적은 부분만을 차지한다.
표 1. 프로그래머블 로직 리소스 할당
그림 3은 원래 애플리케이션의 실행 시간과 맵리듀스 가속기를 이용한 애플리케이션의 실행시간을 비교한 것이다. 이러한 측정값은 모두 자일링스 Zynq SoC 디자인을 기반으로 했다.
맵리듀스 애플리케이션 실행시간
그림 3. 전체 시스템 속도는 애플리케이션에 따라 1.23x에서 1.8x까지 높아졌다.
워드카운트의 경우, 원래의 애플리케이션에서 맵 작업은 워드를 식별하고 이를 리듀스 작업으로 내보낸다. 이 작업은 모든 키/값 쌍을 모으고, 각 키를 위한 값을 축적하게 된다. 가속기의 경우, 맵 작업에서 워드를 식별한 다음, 이 데이터를 고성능 AXI 버스를 통해 맵리듀스 가속장치로 전달한다. 키/값 쌍은 레지스터(각 프로세서마다 다름)에 저장된 다음, 가속기는 메모리 구조에 액세스함으로써 각 키를 위한 값을 모은다.
프로세서 오프로드
실행시간 단축은 리듀스 작업이 키/값 테이블을 먼저 로드한 다음, 필요한 키를 테이블을 통해 검색해야 하는 원래의 코드에서 기인한다. 값이 축적된 이후, 리듀스 작업은 키를 다시 메모리에 저장해야 한다. 우리는 맵리듀스 가속기를 활용함으로써 이 작업을 프로세서에서 오프로드할 수 있었기 때문에 전체 실행시간을 단축할 수 있었다. 쿠쿠 해싱(O(1))은 가속기에서 키 검색시간이 그대로 유지된 반면, 프로세서는 키/값 쌍이 업데이트되는 동안 차단되지 않았다.
그림 3에 나타낸 것처럼, 시스템의 전체 속도가 1.23배에서 1.8배까지 높아졌다. 속도향상은 각 애플리케이션의 특성에 따라 달라진다. 매핑 기능이 보다 복잡한 경우, 맵리듀스 가속기의 속도향상은 적게 나타났다. 전반적인 실행시간이 적게 할당되는 보다 간단한 매핑 기능을 가진 애플리케이션에서는 속도가 크게 향상되었으며, 이는 전체 실행시간의 많은 부분이 맵 및 리듀스 기능 간의 통신에 사용되기 때문이다. 따라서 이 경우, 맵리듀스 가속기는 훨씬 뛰어난 가속을 제공할 수 있다. 또한 맵리듀스 가속기는 프로세서에서 보다 적은 새로운 스레드를 생성하게 되며, 보다 적게 컨텍스트 전환을 하기 때문에 실행시간을 줄일 수 있다. 예를 들어, 워드카운트의 경우, 평균 컨텍스트 전환 수는 88에서 60까지 떨어진다.
맵리듀스 프레임워크는 멀티코어 SoC 및 클라우드 컴퓨팅 애플리케이션을 위한 프로그래밍 프레임워크로 폭넓게 사용이 가능하다. 우리가 제안하는 하드웨어 가속기는 자일링스 Zynq SoC와 같은 멀티코어 SoC 플랫폼 및 맵리듀스 프레임워크 기반 클라우드 컴퓨팅 애플리케이션에서 이러한 애플리케션의 리듀스 작업을 가속함으로써 전체 실행시간을 줄이는데 사용할 수 있다. Zynq SoC 플랫폼 기반 클라우드 컴퓨팅 가속에 대한 보다 자세한 정보는 이 글의 저자인 크리스토포로스 카크리스(Christoforos Kachris, ckachris@ee.duth.gr)에게 연락을 하거나 웹사이트 www.green-center.weebly.com에서 확인할 수 있다.
- 태그 :
- zynq,cuckoo hashing,cloud computing,
- 적용분야 :
- Data Center
- 관련제품 :
- ZYNQ